|
|
You are here: Foswiki>Main Web>Computing>AdministrativeDualPrimaryCluster (01 Jun 2021, WilliamSeligman)Edit Attach
Nevis particle-physics administrative cluster
Background
A single system
In the 1990s, Nevis computing centered on a single computer,nevis1. The majority of the users used this machine to analyze data, access their e-mail, set up web sites, etc. Although the system (an SGI Challenge XL) was relatively powerful for its time, this organization had some disadvantages:
- All the users had to share the processing queues. It was possible that one user could dominate the computer, preventing anyone else from running their own analysis jobs.
- If it became necessary to restart the computer, it had to be scheduled in advance (typically two weeks), since such a restart would affect almost everyone at Nevis.
- If the system's security became compromised, it affected everyone and everything on the system.
A distributed cluster
In the 2000's,nevis1 was gradually replaced by many Linux boxes. Administrative services were moved to separate systems, typically one service per box; e.g., there was a mail server, a DNS server, a Samba server, etc. Each working group at Nevis purchased their own server and managed their own disk space. The above issues were resolved:
- Jobs could be sent to the condor batch system, so that no one system would be slowed down due to a user's jobs.
- A single computer system could be restarted without affecting most of the rest of the cluster; e.g., if the mail server needed to be rebooted, it didn't affect the physics analysis.
- If a server became compromised, e.g., the web server, the effects could be restricted to that server.
- Each working group would purchase and maintain their server with their own funds. However, the administrative servers had to be purchased with Nevis' infrastructure funds. That meant that the administrative servers would be replaced rarely, if at all.
- As a result, the administrative servers tended to be older, recycled, or inexpensive systems, with a correspondingly higher risk of failure.
- At one point there were seven administrative servers in our computer area, each one requiring an uninterruptible power supply, and each one contributing to the power and heat load of the computer room.
High-availability
Tools
Over the last few years, there has been substantial work done in the open-source community towards high-availability servers. To put it simply, a service can be offered by a machine on a high-availability (HA) cluster. If that machine fails, the service automatically transfers to another machine on the HA cluster. The software packages used to implement HA on our cluster are Corosync with Pacemaker. Another open-source development was virtual machines for Linux. If you've ever used VMware, you're already familiar with the concept. The software (actually, a kernel extension) used to implement virtual machines in Linux is called qemu-kvm. The final "piece of the puzzle" is a software package plus kernel extension called DRBD. The simplest way to understand DRBD is to think of it as RAID1 between two computers: when one computer makes a change to a disk partition, the other computer makes the identical change to its copy of the partition. In this way, the disk partition is mirrored between the two systems. These tools can be used to solve the issues listed above:- Six different computers, all old, could be replaced by two new systems.
- The systems could be new, but relatively inexpensive. If one of them failed, the other one would automatically take up the services that the first computer offered.
- The disk images of the two computers, including the virtual machines, could be kept automatically synchronized (as opposed to being copied via a script run at regular intervals).
- Virtual machines are essentially large (~10GB) disk files. They can be manipulated as if they were separate computers (e.g., rebooted when needed) but can also be copied like disk files:
- If a virtual server had its security broken, it could be quickly replaced by a older, un-hacked copy of that virtual machine.
- If a virtual server required a complicated, time-consuming upgrade, a copy could be upgraded instead, then quickly swapped with minimal interruption.
Configuration
The non-HA server
First, let's go over an administrative server that is not part of the HA cluster:hermes. This server provides the following functions:
These services are not part of the HA cluster because: - in the hopefully unlikely event that the HA cluster needs to be rebooted, it's nice to have the services on
hermesstill available during the reboot; - it takes a bit of time for the HA cluster to start up after, e.g., a power outage; again, it's nice to have the above services immediately available.
The HA cluster
The two high-availability servers arehypatia and orestes. hypatia is also the NIS master for the cluster, and a secondary DNS server; these two services are not under the control of the high-availability software.
A sketch of the organization of the high-availability servers:
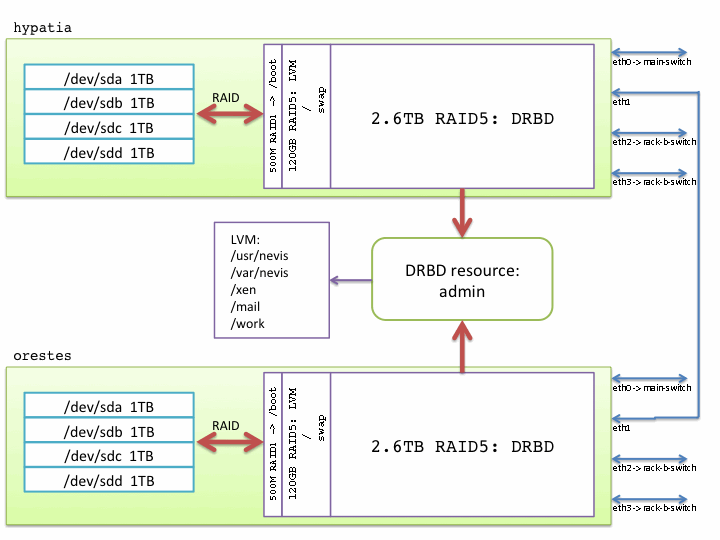
Disk configuration
- Each system has four 1 TB drives, divided into different RAID paritions:
-
/booton a 500MB RAID1. - 120 GB LVM on a RAID5. The LVM is divided into an
/(root) partition and a swap area. - 2.6 TB LVM on a RAID5. This volume is mirrored between
hypatiaandoresteswith DRBD. Within the mirrored partition/dev/drbd1, clustered LVM is used to synchronize logical volumes between the systems. This in turn requires a cluster manager (cman) so each system knows when it has permission to write to the disk, and for each logical volume to be formatted with the gfs2 filesystem. This sounds complicated, because it is... but it's necessary because we're running a dual-primary configuration; these controls are necessary since both systems can write to the same disk at once. - The DRBD volume is carved into logical volumes which are exported to other machines, both real and virtual:
-
/usr/nevisis the application library partition exported to every other system on the Linux cluster. -
/var/neviscontains several resource directories; e.g.,/var/nevis/wwwcontains the Apache web server files;/var/nevis/dhcpdcontains the DHCP work files. -
/mailcontains the work files used by the mail server, including user's INBOXes and IMAP folders. -
/xencontains the disk images of the kvm virtual machines. -
/workis used for backup of the virtual machine disk images, and as a scratch area for cluster maintenance.
-
-
Network configuration
Bothhypatia and orestes have four Ethernet ports: -
eth0is used for network traffic to the Nevis public network and sandbox networks; VLANs are used keep the traffic separate. -
eth1is used for the internal HA cluster traffic; the two systems are connected directly two each other using a single Ethernet cable. For the most part, DRBD uses this port exclusively. -
eth2is used for traffic to the Nevis private network. -
eth3is a "backup" traffic port foreth1. It doesn't happen often, but for some reason the communication on the directly-connectedeth1port is interrupted; this never happens to ports connected to the Ethernet switches. Therefore,eth1andeth3are paired using channel bonding; ifeth1goes down,eth3automatically takes up the traffic.
hypatia and orestes, but this would not be useful if the HA services were cut off on one of the systems. Among the HA resources (see below) that are managed by the systems are "generic" IP addresses assigned to the cluster. The IP name hamilton.nevis.columbia.edu is a cloned IP address that's always available even if one of the systems goes down.
In general, this means that if you need to access a cluster resource remotely, the name hamilton will always work.
Resource sketch
In HA terms, a "resource" means "anything you want to keep available all the time." What follows is an outline of the resources configured for our HA cluster. In this outline, a resource depends on one above it; for example, the mail-server virtual machine won't start if the/xen partition is not available on a given machine. Note the strength of the dual-primary configuration: it's possible for all the resources to run on a single system, if necessary; otherwise the "cloned" resources will run on both systems and the "non-cloned" resources will run on just one of them. (The weakness of the dual-primary setup is its relative complexity over a primary-secondary setup.)
Most of the resources are controlled by scripts provided as part of the Pacemaker package. The resources that begin with lsb:: (Linux standard base) are controlled by the standard scripts found in /etc/init.d/ on most Linux systems.
The current cluster resource status is here. The entire configuration is spelled out in (excruciating) detail on a separate corosync configuration page. There's also a description on what to do if things go wrong.
Services controlled by pacemaker:
AdminClone = the DRBD "admin" partition's main image, cloned as Master (primary) on both systems
FilesystemClone = makes the following available on both systems:
AdminLVM = makes the following logical volumes on the admin partition visible
Filesystem: /usr/nevis
Filesystem: /var/nevis
Filesystem: /mail
Filesystem: /xen
Filesystem: /work
IPClone:
IP = 129.236.252.11 (hamilton = library)
IP = 10.44.7.11
IP = 10.43.7.11
ExportsClone = export /usr/nevis, /var/nevis/, and /mail, which are used by the virtual machines and the rest of the cluster
LibvirtdClone = starts lsb::libvirtd, the virtual machine manager
KVM virtual machines: (not cloned! Each virtual machine runs on only one system)
franklin (= mail; mail server)
ada (= www; web server)
nagios (cluster health monitor)
sullivan (mailing list)
tango (Samba)
hogwarts (= staff accounts for non-login users)
wordpress (blog software)
proxy (web proxying for remote users)
Other resources:
TftpClone (lsb::xinetd for tftp)
Dhcpd (lsb::dhcp)
CronAmbientTemperature (script to monitor computer-room temperature)
CronBackupVirtualDiskImages (bi-montly backup of virtual-machine disk images)
On both systems: the STONITH resources.
References
These are the web sites I used to develop the HA cluster configuration at Nevis.Corosync/Pacemaker
General clustering informationClusters From Scratch - key document for understanding pacemaker configurations
Configuring heartbeat v1 was so simple - elementary notes on pacemaker syntax
Pacemaker Explained - complete guide to pacemaker commands
STONITH Deathmatch Explained - introduction to STONITH concepts
2-Node Redhat KVM Cluster Tutorial - introduction to cman and working with KVM. This only uses Redhat software, so the author uses the weaker rgmanager tool instead of pacemaker. Also, this is a more complex setup than
hypatia/orestes, just in case you thought that our 2-node setup was complicated.
DRBD
DRBD documentationDRBD pages in Clusters From Scratch
Understanding the contents of /proc/drbd
Dealing with DRBD split-brain condition
KVM/QEMU virtual machines
KVM is the name of the virtual machine manager. QEMU is a type of virtual machine. Virtualization Quick Start - skip the first part on installing KVM; focus on thevirsh commands. virsh man page
QEMU documentation
Archive
If you'd like to see the description of previous primary/secondary setup used on the HA cluster, it is here. I switched to a dual-primary setup because:- The secondary server basically did nothing; it just sat around and waited for the primary server to fail. For a while I tried running condor jobs on the secondary server, but that caused problems if the primary server failed before the secondary server had a chance to cancel the jobs.
- The transfer of all the resources to the secondary server after the primary server was STONITHed never seemed to work properly; something was always out of sync. The dual-primary setup is somewhat more robust, since the majority of the resources are already running on both servers.
Edit | Attach | Print version | History: r9 < r8 < r7 < r6 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r8 - 01 Jun 2021, WilliamSeligman
Ideas, requests, problems regarding Foswiki? Send feedback