|
|
You are here: Foswiki>Main Web>Computing>LinuxCluster>DiskSharing (12 May 2021, WilliamSeligman)Edit Attach
Disk sharing and the condor batch system
Background
You don't want to read this page. You just want to submit your jobs and not think about disk files or where they're located. Unfortunately, you have to think about it. Here's why. Picture this: You submit a condor batch procedure that runs thousands of jobs. Each one of those jobs reads and/or writes directly into a directory on your server, accessed via an automount path like/nevis/tanya/data/. Let's say there are 300 batch queues in the Nevis condor system. That means that 300 jobs are trying to access the disk on your server at once.
Sounds like a recipe for disaster, doesn't it? You can crash your server by writing 300 files at once over the network. It's happened several times at Nevis.
There's a bigger problem when that server is one on which users' /home directories are located. The mail server checks your home directory every time you receive a mail message. If your home directory is not available, it slows down the mail server. If the mail server receives a lot of mail for users with home directories on that server, the mail server can slow to the point of uselessness, or crash. If the mail server crashes, the entire Linux cluster can crash.
The choice is between potentially crashing the cluster, and making you think about disk files. It's obvious: thinking is your only option.
Types of systems
In general, these are the types of systems at Nevis:- Administrative systems. These don't run condor, so you'll ignore them.
- Login servers. These are the systems with
/homedirectories. You can login to these system from outside Nevis. - File servers. These are systems with large amounts of disk space. Each collaboration decides whether you can login to these systems from outside Nevis, or only from systems inside Nevis; it's possible you can't login to them at all, but modify their disks via automount.
- Workstations, including the student boxes. If you come to Nevis and you don't have a laptop, you'll use of them. When no one is using a workstation, it's available for condor.
- Batch nodes. They provide processing queues for condor. You can't login to them, and they don't have much disk space. These are the bulk of the systems that run your jobs. (The ATLAS T3 cluster has a different scheme.)
Directories and how they're shared
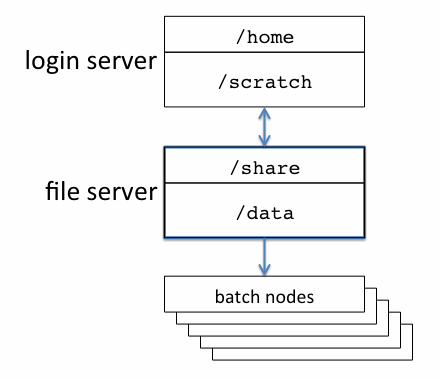
Note: This describes the "ideal" case, which as of Jul-2011 only applies to the Neutrino group. As other groups continue to add and maintain systems on the cluster, I'm going to encourage moving to the separate login/file server configuration. Until then, be careful; crashing the cluster looks like more fun than it is. There are many exceptions (e.g., ATLAS T3), but here are the general rules:- Login servers have a
/homepartition of 100-200 GB, and a/scratchpartition that uses the rest of the available disk space. These partitions are not exported to the batch nodes. - File servers have a
/sharepartition of 100-200GB, and a/datapartition that uses the rest of the available disk space; usually the latter is several TB. These partitions are exported to all the systems in the cluster; in particular, the batch nodes. The/sharepartition is exported read-only to the batch nodes, specifically to keep an automated process from filling it up.
 Important! If you're skimming this page, stop and read this paragraph! The
Important! If you're skimming this page, stop and read this paragraph! The /home and /share partitions are backed up nightly. The other partitions (/scratch, /data, etc.) are not backed up at all.
"OK, I'll put all my stuff where it's backed up." This is a bad strategy: you'll fill up the disk; your jobs will crash; your fellow users will complain. Put files that you personally create (e.g., programs, thesis, plots) on /home or /share. Files that are automatically created (e.g., Monte Carlo output, n-tuples, log files, output files) should be placed in /data or /scratch.
How this affects condor jobs
The only partitions that can be seen by the entire cluster are on your file servers. Therefore, any files that will be read or written by your job should be on/share (for reading) or /data (for reading or writing).
The typical program/job development process looks like this:
- You develop your programs and scripts in your home directory. You run everything interactively. Your output files can be written to
/scratchto avoid filling up the disk. - When you're ready to start running batch jobs, transfer your libraries to
/nevis/<file-server>/share/$USER; e.g., if you're user jsmith and you're working on amsterdam.nevis.columbia.edu, you'll put your libraries and condor scripts in/nevis/amsterdam/share/jsmith; perhaps you'll write your job output and log files to/nevis/amsterdam/data/jsmith.- Don't forget to edit your scripts with the new file paths.
- You may want to re-compile your code in the new location, to make sure the programs knows the new location of your shared libraries.
/data partition. But you'll only crash a file server, not a login server; the entire cluster won't crash. You'll only be in trouble with your group, not with everyone at Nevis.
If you don't want to crash any servers at all, here are some more things to consider:
Let condor transfer the files
Don't rely on your job reading and writing files directly to a particular directory. Use commands like the following in your condor command file; look them up in the User's Manual:should_transfer_files = YES when_to_transfer_output = ON_EXIT transfer_input_files = ...list of input files... initialdir = ...where your inputs and outputs are located...This will transfer your input files to the condor master server once, instead of 300 times; as your job is executing, it will write the output on a local area of the machine that's running the job. Once the job has finished executing, it will transfer the output file to the initialdir directory. Unless you specify a file's full pathname in the condor command file, the files will be copied to and from initialdir (see below). There's one more thing to think about: If
initialdir is located machine A (via automount), and you submit the job from machine B, then condor will use machine B to transfer the files to the directory on machine A. For example, if these lines are in your condor submit file:
initialdir = /nevis/kolya/data/jsmith queue 10000and you submit the job on the machine karthur, then as each of the 10,000 jobs terminates karthur will automount
/nevis/kolya/data/jsmith on kolya to write the file; see condor_shadow for more information. This has not yet caused any machines at Nevis to crash, but it has caused both machines to become annoyingly slow.
Plan where your log files will go
At the end of most condor batch files, you'll see lines that look like this:output = mySimulation-$(Process).out error = mySimulation-$(Process).err log = mySimulation-$(Process).logThese lines define where the job's output, error, and log files are written. If you submit one job, the above lines are fine. If you submit 10,000 jobs, you'll create 30,000 files. If you submit mySimulation1, mySimulation2, ... you'll create an indefinite number of files. If initialdir points to a sub-directory of
/share, sooner or later you'll fill up that disk. Everyone in your group can be affected.
The general solution is to not write your output files into your /share directory. You can do this via one of the following: - submit your job from a directory on the
/datapartition; e.g.,/nevis/<file-server>/data/<$USER>/ - use the initialdir command to tell condor where inputs and outputs are located.
output = /nevis/amsterdam/data/jsmith/myjobs/mySimulation-$(Process).out error = /nevis/amsterdam/data/jsmith/myjobs/mySimulation-$(Process).err log = /nevis/amsterdam/data/jsmith/myjobs/mySimulation-$(Process).logThere is another solution: delete these "scrap" files once you no longer need them. Only the most intelligent and clever physicists remember to do this... and we have high hopes for you!
Edit | Attach | Print version | History: r8 < r7 < r6 < r5 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r7 - 12 May 2021, WilliamSeligman
Ideas, requests, problems regarding Foswiki? Send feedback